
Глибоке занурення в пошук правильного балансу між DDD, Clean та Hexagonal архітектурами
Вибір правильного проєктування програмного забезпечення — це завжди челендж, особливо коли потрібно збалансувати теорію та рекомендації з інтернету з практичною реалізацією. У цій статті я поділюся своїм шляхом та архітектурними рішеннями, які спрацювали для мене.
Хоча назва може наштовхнути на думку, що я тут, щоб точно сказати вам, як структурувати ваш застосунок, це не є моєю метою. Натомість я зосереджусь на своєму особистому досвіді, виборі та причинах підходів, які я обрав під час створення своїх застосунків. Це не означає, що ви повинні структурувати речі так само, але оскільки багато моїх друзів запитували мене про це, я вирішив спробувати пояснити архітектуру, яку ми використовуємо в Cadento (P.S.: особистий проєкт, який я роблю зі своїми друзями; upd: зараз 2025 рік, і він все ще не закінчений :D).
Розумна термінологія#
Ви, напевно, вже знайомі з певними термінами, такими як Clean Architecture (Чиста архітектура), DDD (Domain-driven Design) або, можливо, навіть Hexagonal Architecture (Гексагональна архітектура). Можливо, ви читали багато статей про все це. Але особисто я бачив кілька проблем у більшості з них – занадто багато теоретичної інформації та мало практичної. Вони можуть наводити маленькі та нереалістичні приклади, де все працює ідеально, але це ніколи не працювало для мене і ніколи не давало хороших відповідей, лише збільшувало кількість бойлерплейту.
Деякі з них майже однакові або значною мірою включають один одного і в більшості випадків не суперечать один одному, але багато людей зупиняються на конкретному підході, не думаючи, що це не кінець світу.
Ми спробуємо дізнатися найціннішу інформацію з різних підходів, з яких я черпаю натхнення, окрім того, як я, зокрема, будую свої застосунки. Потім ми перейдемо до моїх конкретних думок та реалізацій. Почнемо з того місця, з якого починає більшість людей при розробці Android-застосунків:
Clean Architecture#
Чиста архітектура звучить досить просто – у вас є конкретні шари, які виконують лише конкретну роботу, що повинна виконуватися лише на конкретному шарі (занадто багато "конкретно", я знаю). Google рекомендує наступну структуру, хоча називає її не "чистою", а "сучасною":
- presentation (презентаційний шар)
- domain (домен / предметна область) (необов'язковий на думку Google)
- data (шар даних)
Презентаційний шар відповідає за ваш інтерфейс користувача (UI), і в ідеалі його єдина роль полягає в комунікації між користувачем (який взаємодіє з UI) та доменною моделлю. Доменний шар обробляє бізнес-логіку, тоді як шар даних займається низькорівневими операціями, такими як читання та запис у базу даних.
Звучить просто, чи не так? Однак у цій структурі криється велике питання: згідно з рекомендованою Google архітектурою для застосунків, чому доменний шар є необов'язковим? Куди ж тоді має діватися бізнес-логіка?
Ця ідея походить від позиції Google, що доменний шар можна пропустити в певних випадках. У простіших застосунках ви можете знайти приклади, де бізнес-логіка розміщена у ViewModel (частина шару презентації). Отже, в чому проблема такого підходу?
Проблема полягає в патернах MVVM/MVI/MVP та ролі шару презентації. Шар презентації повинен обробляти лише інтеграцію з деталями платформи та завдання, пов'язані з UI. У цьому контексті важливо, щоб шар презентації — чи то він використовує MVVM, чи будь-який інший патерн — був вільним від бізнес-логіки. Єдина логіка, яку він повинен містити, стосується вимог, специфічних для платформи.
Чому? У Clean Architecture кожен шар має конкретну відповідальність для забезпечення розділення обов'язків та підтримуваності коду. Завдання шару презентації полягає у взаємодії з користувачем через UI та управлінні операціями, пов'язаними з платформою, такими як відображення (rendering) представлень або обробка вводу. Він не призначений для розміщення бізнес-логіки, оскільки це належить до доменного шару, де централізовані основні правила та прийняття рішень.
Концепція полягає в тому, щоб відокремити специфічні для платформи речі в шарі презентації, що дає можливість змінювати або налаштовувати інтерфейс користувача або платформу без впливу на бізнес-правила та інший код. Наприклад, якби ви хотіли перейти з Android-застосунку на iOS, вам потрібно було б лише переробити UI, зберігши при цьому доменну логіку, що є особливо корисним у контексті Kotlin. 😋
Більшість непорозумінь виникає через нерозуміння того, що таке бізнес-логіка, де вона повинна знаходитися, та природи певних прикладів.
Отже, щоб вирішити інші проблеми, давайте поговоримо більше про доменний шар, зокрема про DDD:
Domain-driven Design#
Предметно-орієнтоване проєктування (DDD) обертається навколо структурування застосунку так, щоб він відображав основну предметну область (домен) бізнесу. Але якщо по-простому – який код слід писати і яким чином?
Ви напевно вже знаєте про репозиторії (Repositories) або юзкейси (Use Cases), і дехто з вас може подумати, що Use Cases є частиною DDD. Але найважливішою частиною є не юзкейси чи репозиторії (я загалом не вважаю їх частиною домену), а доменні об'єкти, навколо яких живе ваша бізнес-логіка.
Доменні об'єкти в DDD – це об'єкти, які відображають бізнес-проблему, яку ви вирішуєте. Це не просто звичайні DTO або POJO, як це часто буває у проєктах початківців. Натомість у DDD доменні об'єкти інкапсулюють як дані, так і поведінку (що включає, наприклад, валідацію). Вони розроблені для представлення реальних концепцій і процесів, і втілюють правила та логіку, що керують цими концепціями.
Існує 3 типи доменних об'єктів у DDD, тож поговорімо про них.
Value objects (Об'єкти-значення)#
Value object – це іммутабельна (immutable) доменна концепція, яка не має власної ідентичності.
Вона ніколи не існує незалежно — вона має сенс лише як частина чогось більшого, зазвичай сутності (entity) або агрегату (aggregate).
Value objects можуть варіюватися від:
- простої обгортки навколо одного значення
- до багатшої структури, що складається з кількох полів
Поки вони є незмінними і не мають ідентичності, вони підходять під цей опис.
Ідентичність, ідентичність... але що це насправді означає? На практиці це означає, що два об'єкти-значення вважаються однаковими, якщо їхні дані однакові. Немає зовнішнього ідентифікатора для порівняння — лише значення, які вони містять.
У Kotlin це природно відображається в data class, де рівність визначається всіма властивостями:
data class Money(
val amount: BigDecimal,
val currency: Currency,
) {
operator fun minus(other: Money) {...}
// інша функціональність
}Тут Money(10, EUR) не відрізняється від іншого Money(10, EUR).
Немає поняття "котрий саме" — тільки "яке значення".
Іншим хорошим використанням об'єктів-значень є семантична типізація — заміна сирих примітивів значущими доменними типами:
@JvmInline
public value class EmailAddress private constructor(public val rawString: String) {
public companion object {
public val LENGTH_RANGE: IntRange = 5..200
public val EMAIL_PATTERN: Regex = Regex(
buildString {
append("[a-zA-Z0-9\\+\\.\_\\%\\-\\+]{1,256}")
append("\\@")
append("[a-zA-Z0-9][a-zA-Z0-9\\-\\*]{0,64}")
append("(")
append("\\.")
append("[a-zA-Z0-9][a-zA-Z0-9\\-\\*]{0,25}")
append(")+")
}
)
public fun create(value: String): Result<EmailAddress> {
return when {
value.size !in LENGTH_RANGE -> Result.failure(...)
!value.matches(EMAIL_PATTERN) -> Result.failure(...)
else -> EmailAddress(value)
}
}
}Ви можете прочитати більше про семантичну типізацію в моїй статті — Семантична типізація, яку ми ігноруємо.
Коротше кажучи, моя загальна порада полягала б у тому, щоб уникати використання сирих типів, таких як String, Int, Long тощо, безпосередньо у вашій доменній моделі (Boolean часто є єдиним розумним винятком).
Натомість впроваджуйте семантичні об'єкти-значення, які:
- є самодокументованими
- інкапсулюють валідацію
- локалізують доменну логіку
- централізують термінологію
- відокремлюють домен від випадкових представлень (даних)
Але що, якщо мій бізнес-об'єкт має стабільну ідентичність? Ось тут у гру вступають доменні сутності.
Domain entities (Доменні сутності / Ентіті)#
Доменна сутність представляє бізнес-концепцію, яка має стабільну ідентичність з часом.
На відміну від об'єктів-значень, сутність не визначається своїми атрибутами, а тим, хто вона є. Її властивості можуть змінюватися, але її ідентичність залишається незмінною.
Прикладом цього може бути UserProfile:
class UserProfile(
val id: UserProfileId,
displayName: DisplayName,
email: EmailAddress,
) {
fun changeDisplayName(
newDisplayName: DisplayName,
): UserProfile =
UserProfile(
id = id,
displayName = newDisplayName,
email = email,
)
fun changeEmail(
newEmail: EmailAddress,
): UserProfile =
UserProfile(
id = id,
displayName = displayName,
email = newEmail,
)
}Незалежно від того, чи змінюємо ми email або ім'я, користувач залишається тим самим. Ідентичність сутності не залежить від її атрибутів — вона закріплена в id, який залишається постійним, навіть коли інші властивості еволюціонують. Це дає зрозуміти, що сутність — це про те, хто вона є, а не що вона наразі має.
Хоча ця версія UserProfile є іммутабельною (immutable) з точки зору мови програмування, вона все одно зберігає свою ідентичність через id. Кожна "зміна" створює новий екземпляр, що представляє ту саму сутність в інший момент часу.
У класичному DDD сутності є змінними (mutable), і багато реалізацій покладаються на це для зручності. Я віддаю перевагу збереженню коду іммутабельним (immutable), коли це можливо, тому що це робить розуміння стану програми, тестування та конкурентність (багатопоточність) набагато безпечнішими, при цьому дотримуючись основного принципу DDD, що сутність визначається її стабільною ідентичністю, а не її атрибутами.
І до нашого "композитора" — Агрегату.
Aggregate (Агрегат)#
У DDD агрегат — це кластер доменних об'єктів — зазвичай сутностей та об'єктів-значень — які розглядаються як єдина межа узгодженості. Агрегат гарантує, що правила та інваріанти домену дотримуються щоразу, коли змінюється або створюється його внутрішній стан.
Інваріант — це бізнес-правило, яке завжди повинно бути істинним для сутності або агрегату. Тоді як об'єкти-значення можуть забезпечувати правила для власних даних (наприклад, EmailAddress гарантує, що має дійсний формат), агрегат може забезпечувати правила вищого рівня, які залучають декілька сутностей або об'єктів-значень разом. Іншими словами, дані можуть бути дійсними окремо, але не узгодженими в контексті агрегату.
class User private constructor(
val id: UserId,
val profile: UserProfile,
val isAdmin: Boolean,
) {
companion object {
// забезпечити інваріант при створенні
fun create(
id: UserId,
profile: UserProfile,
isAdmin: Boolean
): UserCreationResult {
if (isAdmin && !profile.email.value.contains("@business_email.com"))
return UserCreationResult.InvalidAdminEmail
return UserCreationResult.Success(
User(id, profile, isAdmin)
)
}
}
// команда всередині агрегату
fun promoteToAdmin(newEmail: EmailAddress? = null): UserPromotionResult {
val email = newEmail ?: profile.email
val updatedProfile = profile.changeEmail(email)
if (!updatedProfile.email.value.contains("@business_email.com"))
return UserPromotionResult.InvalidAdminEmail
return UserPromotionResult.Success(
User(
id = id,
profile = updatedProfile,
isAdmin = true,
)
)
}
}
sealed interface UserCreationResult {
data class Success(val user: User) : UserCreationResult
object InvalidAdminEmail : UserCreationResult
}
sealed interface UserPromotionResult {
data class Success(val user: User) : UserPromotionResult
object InvalidAdminEmail : UserPromotionResult
}У цьому прикладі всі створення та зміни стану проходять через типобезпечні фабрики та команди, гарантуючи, що інваріанти ніколи не будуть обійдені. Дуже важливо, щоб наш домен підтримував узгодженість, а дані залишалися дійсними протягом усього життєвого циклу.
Сілд-інтерфейси (sealed interfaces) для результатів роблять опис можливих станів явним і самодокументованим, дозволяючи компілятору примушувати до обробки як успішних, так і невдалих випадків. Пряме створення екземпляра User запобігається за допомогою private constructor, тому кожен екземпляр повинен пройти через логіку валідації в create або promoteToAdmin.
Самі агрегати також мають межі, які ми повинні поважати. Ви не можете просто вбудувати один агрегат в інший, оскільки кожен агрегат відповідає за свої власні інваріанти та правила узгодженості. Наприклад, агрегат Team (Команда) не може містити агрегати User безпосередньо; проте, як воркераунд (workaround, він може зберігати посилання на їхні ID.
class Team private constructor(
id: TeamId,
name: TeamName,
memberIds: Set<UserId> // посилання на агрегати User за ID
) {
companion object {
fun create(
id: TeamId,
name: TeamName,
memberIds: Set<UserId>
): Team {
// може бути надійніша валідація
require(memberIds.isNotEmpty()) { "Team must have at least one member" }
return Team(id, name, memberIds)
}
}
fun addMember(userId: UserId): Team =
Team(id, name, memberIds + userId)
fun removeMember(userId: UserId): Team =
Team(id, name, memberIds - userId)
}Це зберігає правила чіткими: Team забезпечує власні інваріанти, тоді як User забезпечує свої, і вони взаємодіють безпечно через ID, а не змішуючи свої внутрішні стани. Це схоже на надання кожному агрегату власного робочого простору — вони можуть співпрацювати, але ніколи не наступати один одному на п'яти.
Окрім Агрегатів, Доменних сутностей та Об'єктів-значень, іноді ви можете бачити сервісні класи доменного шару. Вони використовуються для логіки, яку зазвичай не можна розмістити в агрегатах, але яка все ж є свого роду бізнес-логікою. Наприклад:
class ShippingService {
fun calculatePrice(
order: Order,
shippingAddress: ShippingAddress,
shippingOption: ShippingOption,
): Price {
return if (order.product.country == shippingAddress.country)
order.price
else order.price + someFee
}
}Ми не будемо обговорювати корисність чи ефективність сервісів доменного рівня чи агрегаторів на даному етапі. Просто майте це на увазі, поки ми не дійдемо до моменту, коли об'єднаємо ці підходи в одне ціле.
Але це майже все – реалізація може відрізнятися від проєкту до проєкту, і єдине, що я використовую як правило для всього – це незмінність (immutability), коли це можливо.
Проблеми#
Анемічні доменні сутності (Anemic Domain Entities / Ентіті)#
Анемічна доменна модель (Anemic Domain Model) — це поширений антипатерн у DDD, де доменні об'єкти — ентіті та об'єкти-значення — зводяться до пасивних контейнерів даних, які не мають поведінки і містять лише геттери та сеттери (якщо ми не в Kotlin, де це властивості). Ця модель вважається "анемічною", оскільки вона не інкапсулює бізнес-логіку, яка повинна жити в самому домені. Натомість ця логіка часто витісняється в окремі сервіси або юзкейси, що призводить до проблем у дизайні.
Щоб краще зрозуміти проблему, що саме поганого в анемічних ентіті? Розгляньмо:
- Складність у розумінні можливостей ентіті: Коли логіка розкидана по контролерах або юзкейсах (Use Cases), важче відстежувати обов'язки об'єкта, що сповільнює дебаг та онбординг (також врахуйте, що бізнес-логіку в юзкейсах важче шукати при код-рев'ю).
- Порушення інкапсуляції: Ентіті містять лише дані, виштовхуючи логіку в сервіси. Це змушує вас вручну узгоджувати логіку між різними юзкейсами та контролерами.
- Важче тестувати: Коли поведінка розсіяна, юніт-тестування окремих функцій стає складнішим, оскільки логіка не згрупована всередині об'єкта.
- Дублювання логіки: Бізнес-правила часто повторюються в різних юзкейсах, що призводить до непотрібного копіпасту та витрат на підтримку.
Приклад поганої бізнес-сутності:
sealed interface TimerState : State<TimerEvent> {
override val alive: Duration
override val publishTime: UnixTime
data class Paused(
override val publishTime: UnixTime,
override val alive: Duration = 15.minutes,
) : TimerState {
override val key: State.Key<*> get() = Key
companion object Key : State.Key<Paused>
}
data class ConfirmationWaiting(
override val publishTime: UnixTime,
override val alive: Duration,
) : TimerState {
override val key: State.Key<*> get() = Key
companion object Key : State.Key<ConfirmationWaiting>
}
data class Inactive(
override val publishTime: UnixTime,
) : TimerState {
override val alive: Duration = Duration.INFINITE
override val key: State.Key<*> get() = Key
companion object Key : State.Key<Inactive>
}
running(
override val publishTime: UnixTime,
override val alive: Duration,
) : TimerState {
override val key: State.Key<*> get() = Key
companion object Key : State.Key<Running>
}
data class Rest(
override val publishTime: UnixTime,
override val alive: Duration,
) : TimerState {
override val key: State.Key<*> get() = Key
companion object Key : State.Key<Rest>
}
}Це просто контейнери з даними про стани Cadento. Питання в тому: як ми можемо перетворити цю анемічну доменну сутність на багату?
У цьому випадку для станів у мене був інший контролер, який обробляв усі переходи та події:
class TimersStateMachine(
timers: TimersRepository,
sessions: TimerSessionRepository,
storage: StateStorage<TimerId, TimerState, TimerEvent>,
timeProvider: TimeProvider,
coroutineScope: CoroutineScope,
) : StateMachine<TimerId, TimerEvent, TimerState> by stateMachineController({
initial { TimerState.Inactive(timeProvider.provide()) }
state(TimerState.Inactive, TimerState.Paused, TimerState.Rest) {
onEvent { timerId, state, event ->
// ...
}
onTimeout { timerId, state ->
// ...
}
// ...
}Окрім гарного вигляду, це порушує принципи DDD – доменний об'єкт повинен представляти не лише дані, але й поведінку. Сутність повинна бути такою:
sealed interface TimerState : State<TimerEvent> {
override val alive: Duration
override val publishTime: UnixTime
// Тепер бізнес-сутність може сама реагувати на події;
// Ці функції є 'агрегатами' з DDD;
fun onEvent(event: TimerEvent, settings: TimerSettings): TimerState
fun onTimeout(
settings: TimerSettings,
currentTime: UnixTime,
): TimerState
data class Paused(
override val publishTime: UnixTime,
override val alive: Duration = 15.minutes,
) : TimerState {
override val key: State.Key<*> get() = Key
companion object Key : State.Key<Paused>
override fun onEvent(
event: TimerEvent,
settings: TimerSettings,
): TimerState {
return when (event) {
TimerEvent.Start -> if (settings.isConfirmationRequired) {
TimerState.ConfirmationWaiting(publishTime, 30.seconds)
} else {
TimerState.Running(publishTime, settings.workTime)
}
else -> this
}
}
override fun onTimeout(
settings: TimerSettings,
currentTime: UnixTime,
): TimerState {
return Inactive(currentTime)
}
}
// ...
}Примітка: Іноді деяка логіка поміщається в UseCases, і це може бути менш очевидним, ніж у цьому конкретному випадку.
Дивлячись на таку сутність, ви швидше розумієте, що вона робить, як реагує на події домену та інші речі, що можуть статися.
Але, що стосується бізнес-об'єктів, іноді ви можете відчувати, що вони не мають жодної поведінки, яку ви могли б додати/перемістити в них. Ось мій приклад такого об'єкта:
data class User(
val id: UserId,
val name: UserName,
emailAddress: EmailAddress?,
description: UserDescription?,
avatar: Avatar?,
) {
data class Patch(
val name: UserName? = null,
description: UserDescription? = null,
avatar: Avatar?,
)
}Цікава примітка: Це реальний код з мого домену користувача з такою проблемою.
Потенційна проблема полягає в тому, що User і Patch є контейнерами даних без бізнес-логіки. Перш за все, я використовую Patch тільки в UseCases, що означає, що він повинен бути розміщений там, де він потрібен. Використовуйте це правило для всього – оголошення без використання на шарі, який його визначає, означає, що ви робите щось не так.
Що стосується User, немає необхідності створювати функції-агрегати – автоматично згенерованого Kotlin методу copy більш ніж достатньо, оскільки об'єкти-значення вже валідовані, і для всієї сутності немає спеціальної логіки для цього.
Щоб дізнатися більше про цю проблему, ви можете звернутися, наприклад, до цієї статті.
Я б додав, що вам слід намагатися уникати анемічних доменних сутностей, але водночас не змушуйте себе – якщо немає чого агрегувати, не додавайте агрегати. Не вигадуйте поведінку, якщо нічого вигадувати – KISS все ще діє.
Ігнорування єдиної мови (Ubiquitous Language)#
Ubiquitous Language (Єдина мова), ключова концепція в DDD, часто ігнорується. Доменна модель і код повинні використовувати ту саму мову, що й бізнес-стейкхолдери, щоб зменшити непорозуміння. Неузгодженість коду з мовою експертів домену призводить до розриву між бізнес-логікою та фактичною реалізацією.
Простими словами, імена повинні бути легко зрозумілими навіть для непрограмістів. Це особливо корисно для великих проєктів із залученням кількох команд з різними знаннями, навичками та обов'язками.
Це дрібниця, якої слід дотримуватися, але дуже важлива. Я б додав, що одні й ті самі концепції не повинні мати різні назви в різних доменах – це заплутує навіть в межах однієї команди.
Тепер перейдемо до іншого підходу, який я використовую у своїх проєктах – Гексагональна архітектура:
Hexagonal Architecture#
Гексагональна архітектура, також відома як Порти та Адаптери, розглядає структурування застосунків під іншим кутом порівняно з традиційними підходами. Вона полягає в ізоляції основної доменної логіки від зовнішніх систем — так, щоб основна бізнес-логіка не залежала від фреймворків, баз даних або інших інфраструктурних проблем. Цей підхід сприяє тестованості та підтримуваності, і він добре узгоджується з DDD в тому, що фокус залишається на бізнес-логіці.
Існує два типи Портів – Inbound (вхідні) та Outbound (вихідні).
- Вхідні порти визначають операції, які зовнішній світ може виконувати над основним доменом.
- Вихідні порти визначають сервіси, які домену потрібні від зовнішнього світу.
Різниця між DDD та Гексагональною архітектурою в стратегії ізоляції концептуально однакова, але друга виводить її на новий рівень. Гексагональна архітектура визначає, як ви повинні спілкуватися з вашою доменною моделлю.
Отже, наприклад, якщо вам потрібно отримати доступ до зовнішнього сервісу або функції, щоб зробити щось у вашому домені, ви робите наступне:
interface GetCurrentUserPort {
suspend fun execute(): Result<User>
}
class TransferMoneyUseCase(
private val balanceRepository: BalanceRepository,
private val getCurrentUser: GetCurrentUserPort
) {
suspend fun execute(): ... {
val currentUser = getCurrentUser.execute()
val availableAmount = balanceRepository.getCurrentBalance(user.id)
// ... логіка переказу
}
// ...
}UseCases зазвичай вважаються вхідними портами, оскільки вони представляють операції або взаємодії, ініційовані зовнішнім світом. Однак назви та реалізація можуть відрізнятися.
У своїх проєктах я зазвичай не ввожу іншу термінологію і зазвичай просто створюю інтерфейс репозиторію, який мені потрібен ззовні:
interface UserRepository {
suspend fun getCurrentUser(): Result<User>
// ... інші методи
}Я консолідую все в єдиний репозиторій, щоб уникнути непотрібного створення класів, надаючи чіткішу абстракцію для більшості людей, знайомих з концепцією репозиторію.
Не завжди може бути так, що вам потрібно викликати репозиторій з іншої фічі (feature) або системи. Іноді ви можете захотіти викликати іншу бізнес-логіку, яка обробляє те, що вам потрібно (що може бути набагато краще), відому як UseCases. У цьому сценарії прийнято мати окремий інтерфейс від першого прикладу.
Ось візуалізація:
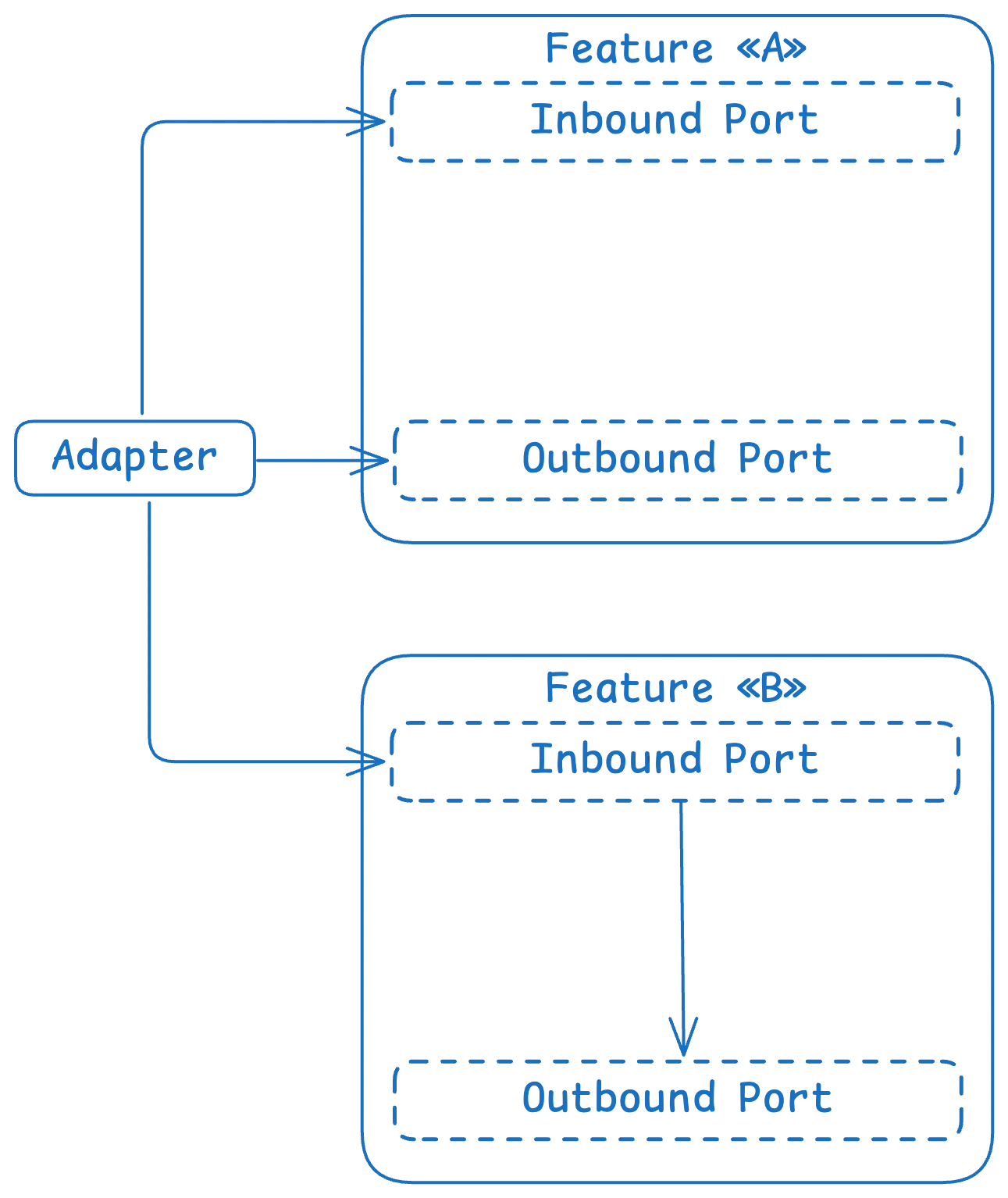
Примітка: До речі, інша термінологія для 'фічі' (feature) — це 'обмежений контекст' (bounded context) з DDD. Вони означають майже те саме.
Приклад визначення та використання портів, що відповідає схемі вище:
// FEATURE «A»
// Вихідний порт для отримання користувача з іншої фічі (обмеженого контексту)
interface GetUserPort {
fun getUserById(userId: UserId): User
}
class TransferMoneyUseCase(private val getUserPort: GetUserPort) : TransferService {
override suspend fun transfer(
val userId: UserId, val amount: USDAmount
): Boolean {
val user = getUserPort.getUserById(request.userId)
if (user.balance >= request.amount) {
println("Transferring ${request.amount} to ${user.name}")
return true
}
println("Insufficient balance for ${user.name}")
return false
}
}Реалізація портів здійснюється через Адаптери – це, по суті, просто зв'язка, яка реалізує ваш інтерфейс для роботи із зовнішньою системою. Назва такого шару може варіюватися – від простого data або integration до прямого adapters. Вони досить взаємозамінні і залежать від конкретних конвенцій про іменування в проєкті. Цей шар зазвичай реалізує інші домени та використовує інші Порти для досягнення того, що йому потрібно.
Ось приклад реалізації GetUserPort:
// UserService — це сервіс з іншої фічі (B)
// Адаптери зазвичай знаходяться в окремому модулі, тому що вони залежать від
// іншого домену, щоб уникнути прямого зв'язування.
class GetUserAdapter(private val getUserUseCase: GetUserUseCase) : GetUserPort {
override fun getUserById(userId: String): User? {
return userService.findUserById(userId)
}
}Отже, фічі пов'язані лише на рівні даних/адаптерів. Перевага цього полягає в тому, що ваша доменна логіка залишається незмінною незалежно від того, що відбувається із зовнішньою системою. Це ще одна причина, чому порти домену насправді не повинні відповідати всьому, що хоче зовнішня система – це відповідальність Адаптера розібратися з цим. Під цим я маю на увазі, що, наприклад, сигнатура функції може відрізнятися від тієї, що використовується в зовнішній системі, якщо, звичайно, це дозволяє реалізувати дану функціональність.
Інша річ, яку важливо враховувати, — це те, як обробляти типи домену. Фічі рідко бувають повністю ізольованими від інших типів фіч. Наприклад, якщо у нас є бізнес-об'єкт під назвою User і об'єкт-значення UserId, нам часто потрібно повторно використовувати ID користувача для зберігання інформації, пов'язаної з користувачем. Це створює потребу знайти спосіб повторного використання цього типу в різних частинах системи.
В ідеальній гексагональній архітектурі різні домени повинні існувати незалежно. Це означає, що кожен домен повинен мати свої специфічні визначення типів, які вони використовують. Простіше кажучи, це вимагає від вас повторного оголошення цих типів щоразу, коли вони вам потрібні.
Це створює багато дублювання, шаблонного коду під час перетворення кожного типу між окремими доменами, проблеми з валідацією (особливо якщо вимоги змінюються з часом, ви можете щось упустити), і це просто великий біль у житті будь-якого розробника.
Порада полягає в тому, що ви не повинні дотримуватися всіх цих правил, поки не побачите переваги. Шукайте золоту середину, маючи справу з цим; як я впорався з цим, ми обговоримо в наступній частині.
Проблеми#
Неправильна ментальна модель#
Щодо помилок, які я бачу найчастіше – розробники не розуміють, що шари Домену та Програми (Application) – це не просто фізичний поділ, а правильна ментальна модель. Дозвольте пояснити:
Ментальна модель – це концептуальне представлення роботи або структури різних частин системи, які взаємодіють одна з одною (простіше кажучи, як код сприймається тими, хто його використовує). Вона відрізняється від фізичної моделі тим, що фізична модель передбачає фізичну взаємодію - наприклад, виклик певної функції або реалізацію модуля, тобто все, що робиться руками.
Поширеною проблемою в проєктуванні програмного забезпечення є дозвіл шару домену/програми знати про зберігання або джерела даних, що порушує принцип розділення обов'язків. Фокус домену повинен залишатися на бізнес-логіці, незалежно від джерел даних. Однак ви можете зустріти приклади, такі як LocalUsersRepository або RemoteUsersRepository, і відповідні сценарії використання, такі як GetCachedUserUseCase або GetRemoteUserUseCase в шарі програми (у випадку, якщо репозиторії розміщені в домені, я зазвичай розміщую їх там, де я їх використовую — в шарі програми, але проблема залишається). Хоча це може вирішити конкретну проблему, це порушує ментальну модель домену, яка повинна залишатися агностичною до джерела даних.
Те саме стосується DAO в контексті фреймворків, таких як androidx.room. Вони не лише порушують правило не говорити про джерело даних, але й додатково порушують правило незалежності від будь-яких фреймворків.
Ваші репозиторії/usecases повинні триматися подалі від джерела даних, навіть якщо це може здаватися нормальним у ситуаціях, коли реалізація не знаходиться безпосередньо в доменному/програмному шарі.
Моя реалізація#
Закінчивши пояснення підходів, які я використовую, я хотів би перейти до моєї фактичної реалізації та того, як я впорався зі зменшенням непотрібного шаблонного коду та абстракцій.
Почнемо з визначення ключових ідей кожного підходу, який ми обговорили:
- Clean Architecture: розділіть ваш код на різні шари за їхньою відповідальністю (domain, data, presentation)
- Domain-driven Design: Домен повинен містити лише бізнес-логіку, всі типи повинні бути узгодженими та дійсними протягом усього їх життєвого циклу.
- Hexagonal Architecture: Суворі правила доступу до внутрішнього та зовнішнього світів.
Вони ідеально підходять один одному здебільшого, що є ключем до написання хорошого коду.
Структура функцій (фіч) Cadento (різних доменів) наступна:
- domain (домен)
- data (реалізує все, що пов'язано зі зберіганням або управлінням мережею, включаючи підмодулі з DataSources)
- database (інтеграція з SQLDelight, автоматично згенеровані DataSources)
- network (насправді, у мене цього немає в Cadento, тому що це замінено на Cadento SDK, але якби не було, я б додав це)- dependencies (інтеграційний шар з Koin)
- database (інтеграція з SQLDelight, автоматично згенеровані DataSources)
- presentation (UI з Compose та MVI)
Мені подобається ця структура, але ви можете захотіти відокремити UI від ViewModels, щоб мати можливість використовувати різні UI-фреймворки для кожної платформи; я не планую цього робити, тому залишаю все як є. Але якщо я зіткнуся з таким викликом у майбутньому, це не складно для мене, оскільки я не залежу від Compose у ViewModels (чому ви також маєте слідувати).
Головною проблемою, з якою я зіткнувся, був шаблонний код, який я мав під час реалізації DDD та гексагональної архітектури – я копіював і вставляв типи, що змушувало мене замислитися: 'Чи справді мені це потрібно?'. Тож я придумав наступні правила:
- У мене є спільні основні типи, які повторно використовуються різними системами; це свого роду об'єднаний домен найбільш потрібних типів.
- Тип може бути спільним лише в тому випадку, якщо він використовується в більшості доменів, має проблему з дублюванням валідації і взагалі не є складною структурою (іноді бувають винятки, але зазвичай їх небагато).
Що я маю на увазі під 'складною структурою'? Зазвичай ваш домен, який вимагає типу іншого домену, не потребує всього, що описано в даному типі. Наприклад, ви можете захотіти поділитися типом 'User' разом з його об'єктами-значеннями, але здебільшого інші домени не потребують всього від типу User і можуть хотіти, наприклад, лише ім'я та ID. Я намагаюся уникати таких ситуацій, і навіть якщо щось вже є в основних типах домену, я б краще створив окремий тип з інформацією, яка потрібна моєму певному домену. Але щодо валідації, я ділюся майже всіма семантичними об'єктами-значеннями.
Ви можете розширити цю ідею для більших проєктів, створюючи не просто спільні основні типи, а типи для конкретних областей, де працює певна група ваших піддоменів (обмежених контекстів).
Підсумовуючи, я повторно використовую об'єкти-значення, які мають однакові правила валідації в одному спільному модулі; я намагаюся не робити мій модуль спільних основних типів занадто великим. Завжди має бути золота середина.
Крім того, у моїх проєктах у мене немає терміну 'Inbound Ports'. Я повністю замінюю їх на UseCases:
class GetTimersUseCase(
private val timers: TimersRepository,
private val fsm: TimersStateMachine,
) {
suspend fun execute(
auth: Authorized<TimersScope.Read>,
pageToken: PageToken?,
pageSize: PageSize,
): Result {
val infos = timers.getTimersInformation(
auth.userId, pageToken, pageSize,
)
val ids = infos.map(TimersRepository.TimerInformation::id)
val states = ids.map { id -> fsm.getCurrentState(id) }
return Result.Success(
infos.mapIndexed { index, information ->
information.toTimer(
states.value[index]
)
},
)
}
sealed interface Result {
data class Success(
val page: Page<Timer>,
) : Result
}
}Примітка: це приклад з Cadento Backend
Він не порушує Гексагональну архітектуру або DDD, що робить його хорошим способом визначення того, як зовнішній світ отримує доступ до вашого домену. Він має те саме значення і поведінку, що і вхідний порт.
Щодо вихідних портів, я зробив те саме, що я наводив раніше в прикладах.
Висновок#
У своїх проєктах я волію залишати речі практичними. Хоча теорія та абстракція корисні, вони можуть надмірно ускладнити прості речі. Ось чому я поєдную сильні сторони Clean Architecture, DDD та Hexagonal Architecture, не дотримуючись їх занадто суворо. Використовуйте критичне мислення, щоб визначити, що вам насправді потрібно і чому це приносить користь вашому проєкту, а не сліпо слідуйте рекомендаціям.
Прямі згадки1
Непрямі згадки0
Немає непрямих згадок.

