
Das richtige Gleichgewicht zwischen DDD, Clean und Hexagonal Architekturen finden
Die Wahl der richtigen Softwaredesign ist eine Herausforderung, insbesondere wenn es darum geht, Theorie und Empfehlungen aus dem Internet mit der praktischen Umsetzung in Einklang zu bringen. In diesem Artikel werde ich meine Reise und die architektonischen Entscheidungen, die für mich funktioniert haben, teilen.
Obwohl der Titel suggerieren mag, dass ich Ihnen genau sagen werde, wie Sie Ihre Anwendung strukturieren sollen, ist das nicht mein Ziel. Stattdessen werde ich mich auf meine persönlichen Erfahrungen, Entscheidungen und die Gründe für die Ansätze konzentrieren, die ich beim Erstellen meiner Apps gewählt habe. Das bedeutet nicht, dass Sie die Dinge auf die gleiche Weise strukturieren sollten, aber da viele meiner Freunde mich danach gefragt haben, dachte ich, ich würde versuchen, die Architektur zu erklären, die wir in Cadento verwenden (P.S.: persönliches Projekt, das ich mit meinen Freunden mache; Upd: es ist 2025 und es ist immer noch nicht fertig :D).
Smarte Terminologie#
Sie kennen wahrscheinlich bereits bestimmte Begriffe wie Clean Architecture, DDD (Domain-driven Design) oder vielleicht sogar Hexagonale Architektur. Vielleicht haben Sie schon viele Artikel darüber gelesen. Aber ich persönlich sah in den meisten davon einige Probleme – zu viel theoretische Information und zu wenig praktische Information. Sie mögen Ihnen kleine und unrealistische Beispiele geben, bei denen alles perfekt funktioniert, aber das hat bei mir nie funktioniert und mir nie gute Antworten gegeben, sondern nur die Menge an Boilerplate erhöht.
Einige davon sind fast identisch oder umfassen sich größtenteils gegenseitig und widersprechen sich in den meisten Fällen nicht, aber viele Leute bleiben bei einem spezifischen Ansatz stehen und denken nicht, dass es nicht das Ende der Welt ist.
Wir werden versuchen, die wertvollsten Informationen aus verschiedenen Ansätzen, von denen ich mich inspirieren lasse, zu lernen, abgesehen davon, wie ich meine Apps zunächst baue. Dann kommen wir zu meinen speziellen Gedanken und Implementierungen. Beginnen wir dort, wo die meisten Leute bei der Entwicklung von Android-Apps anfangen:
Clean Architecture#
Clean Architecture klingt ziemlich einfach – Sie haben spezifische Schichten, die jeweils nur eine spezifische Aufgabe erfüllen sollen (ich weiß, zu viel spezifisch). Google empfiehlt die folgende Struktur, nennt sie aber nicht "clean", sondern "modern":
- Präsentation
- Domäne (optional nach Googles Meinung)
- Daten
Die Präsentationsschicht ist für Ihre Benutzeroberfläche verantwortlich, und idealerweise besteht ihre einzige Rolle darin, zwischen dem Benutzer (der mit der Benutzeroberfläche interagiert) und dem Domänenmodell zu kommunizieren. Die Domänenschicht behandelt die Geschäftslogik, während die Datenschicht sich mit Low-Level-Operationen wie dem Lesen und Schreiben in eine Datenbank befasst.
Klingt einfach, oder? Doch innerhalb dieser Struktur liegt eine große Frage: Laut der von Google empfohlenen Architektur für Apps, warum ist die Domänenschicht optional? Wo soll dann die Geschäftslogik hin?
Diese Idee kommt von Googles Standpunkt, dass die Domänenschicht in bestimmten Fällen übersprungen werden kann. In einfacheren Anwendungen finden Sie möglicherweise Beispiele, bei denen die Geschäftslogik in der ViewModel (Teil der Präsentationsschicht) platziert wird. Was ist also das Problem bei diesem Ansatz?
Das Problem liegt in den MVVM/MVI/MVP-Mustern und der Rolle der Präsentationsschicht. Die Präsentationsschicht sollte nur die Integration mit Plattformdetails und UI-bezogene Aufgaben behandeln. In diesem Kontext ist es entscheidend, die Präsentationsschicht – ob sie MVVM oder ein anderes Muster verwendet – frei von Geschäftslogik zu halten. Die einzige Logik, die sie enthalten sollte, bezieht sich auf plattformspezifische Anforderungen.
Warum? In der Clean Architecture hat jede Schicht eine spezifische Verantwortung, um die Trennung der Belange und wartbaren Code sicherzustellen. Die Aufgabe der Präsentationsschicht besteht darin, mit dem Benutzer über die Benutzeroberfläche zu interagieren und plattformbezogene Operationen wie das Rendern von Ansichten oder das Handhaben von Eingaben zu verwalten. Sie soll keine Geschäftslogik enthalten, da diese in die Domänenschicht gehört, wo die Kernregeln und Entscheidungsfindung zentralisiert sind.
Das Konzept besteht darin, plattformspezifische Überlegungen in der Präsentationsschicht zu trennen, wodurch es möglich wird, die Benutzeroberfläche oder Plattform zu ändern oder anzupassen, ohne die Geschäftsregeln und andere Codes zu beeinflussen. Wenn Sie beispielsweise von einer Android- zu einer iOS-App wechseln möchten, müssten Sie nur die Benutzeroberfläche überarbeiten, während die Domänenlogik erhalten bleibt, was im Kontext von Kotlin besonders vorteilhaft ist. 😋
Die meisten Missverständnisse rühren daher, dass nicht verstanden wird, was Geschäftslogik ist, wo sie sich befinden sollte und die Art bestimmter Beispiele.
Um weitere Probleme anzugehen, sprechen wir mehr über die Domänenschicht, insbesondere über DDD:
Domain-driven Design#
Domain-driven Design (DDD) dreht sich um die Strukturierung der Anwendung, um den Kern der Geschäftsdomäne widerzuspiegeln. Aber einfach – welcher Code sollte wie geschrieben werden?
Sie kennen sicherlich bereits Repositories oder UseCases und einige von Ihnen denken vielleicht, dass UseCases ein Teil davon sind. Aber der wichtigste Teil sind nicht UseCases oder Repositories (ich betrachte sie insgesamt nicht als Teil einer Domäne), sondern Geschäftsobjekte, um die Ihre Domänenlogik lebt.
Domänenobjekte im DDD-Bereich sind essentielle Objekte, die das Geschäftsproblem widerspiegeln, das Sie ansprechen. Es sind nicht nur gewöhnliche DTOs oder POJOs, wie sie häufig in vielen Anfängerprojekten verwendet werden. Stattdessen kapseln Domänenobjekte in DDD sowohl Daten als auch Verhalten (das schließt zum Beispiel Validierung ein). Sie sind darauf ausgelegt, reale Konzepte und Prozesse darzustellen und verkörpern die Regeln und Logik, die diese Konzepte steuern. Aber was ist der einfache Ratschlag, der sich daraus ergibt?
Es gibt 3 Arten von Domänenobjekten innerhalb von DDD, also lassen Sie uns über sie sprechen.
Value Objects#
Ein Value Object (Wertobjekt) ist ein unveränderliches Domänenkonzept, das keine eigene Identität hat.
Es existiert nie unabhängig – es macht nur Sinn als Teil von etwas Größerem, normalerweise einer Entität oder einem Aggregat.
Value Objects können reichen von:
- einem einfachen Wrapper um einen einzelnen Wert
- bis zu einer reichhaltigeren Struktur, die aus mehreren Feldern besteht
Solange sie unveränderlich und identitätslos sind, qualifizieren sie sich.
Identität, identität... aber was bedeutet das wirklich? In der Praxis bedeutet das, dass zwei Value Objects als gleich betrachtet werden, wenn ihre Daten gleich sind. Es gibt keinen externen Bezeichner zum Vergleichen – nur die Werte, die sie enthalten.
In Kotlin lässt sich dies natürlich auf eine data class abbilden, wo Gleichheit von allen Eigenschaften abgeleitet wird:
data class Money(
val amount: BigDecimal,
val currency: Currency,
) {
operator fun minus(other: Money) {...}
// andere Funktionalität
}Hier ist Money(10, EUR) nicht von einem anderen Money(10, EUR) zu unterscheiden.
Es gibt kein Konzept von „welchem" – nur „welcher Wert".
Eine weitere mächtige Anwendung von Value Objects ist das semantische Typing – das Ersetzen roher Primitive durch bedeutungsvolle Domänentypen:
@JvmInline
public value class EmailAddress private constructor(public val rawString: String) {
public companion object {
public val LENGTH_RANGE: IntRange = 5..200
public val EMAIL_PATTERN: Regex = Regex(
buildString {
append("[a-zA-Z0-9\\+\\.\\_\\%\\-\\+]{1,256}")
append("\\@")
append("[a-zA-Z0-9][a-zA-Z0-9\\-]{0,64}")
append("(")
append("\\.")
append("[a-zA-Z0-9][a-zA-Z0-9\\-]{0,25}")
append(")+")
}
)
public fun create(value: String): Result<EmailAddress> {
return when {
value.size !in LENGTH_RANGE -> Result.failure(...)
!value.matches(EMAIL_PATTERN) -> Result.failure(...)
else -> EmailAddress(value)
}
}
}
}Sie können mehr über semantisches Typing in meinem Artikel lesen — Semantische Typisierung, die wir ignorieren.
Kurz gesagt, mein allgemeiner Rat wäre, die direkte Verwendung von rohen Typen wie String, Int, Long usw. in Ihrem Domänenmodell zu vermeiden (Boolean ist oft die einzige vernünftige Ausnahme).
Führen Sie stattdessen semantische Value Objects ein, die:
- selbsterklärend sind
- Validierung kapseln
- Domänenlogik lokalisieren
- Terminologie zentralisieren
- die Domäne von zufälligen Darstellungen entkoppeln
Aber was ist, wenn mein Geschäftsobjekt eine stabile Identität hat? Hier kommen Domänen-Entitäten ins Spiel.
Domänen-Entitäten (Domain Entities)#
Eine Domänen-Entität repräsentiert ein Geschäftskonzept, das eine stabile Identität über die Zeit hinweg hat.
Im Gegensatz zu Value Objects wird eine Entität nicht durch ihre Attribute definiert, sondern dadurch, wer sie ist. Ihre Eigenschaften können sich ändern, aber ihre Identität muss gleich bleiben.
Ein Beispiel dafür kann UserProfile sein:
class UserProfile(
val id: UserProfileId,
displayName: DisplayName,
email: EmailAddress,
) {
fun changeDisplayName(
newDisplayName: DisplayName,
): UserProfile =
UserProfile(
id = id,
displayName = newDisplayName,
email = email,
)
fun changeEmail(
newEmail: EmailAddress,
): UserProfile =
UserProfile(
id = id,
displayName = displayName,
email = newEmail,
)
}Egal, ob wir die E-Mail oder den Anzeigenamen ändern, der Benutzer ist immer noch derselbe. Die Identität der Entität hängt nicht von ihren Attributen ab – sie ist in der ID verankert, die konstant bleibt, auch wenn sich andere Eigenschaften entwickeln. Das macht deutlich, dass es bei einer Entität darum geht, wer sie ist, nicht was sie derzeit hat.
Obwohl diese Version von UserProfile unveränderlich ist, bewahrt sie ihre Identität dennoch durch die id. Jede „Änderung" erzeugt eine neue Instanz, die dieselbe Entität zu einem anderen Zeitpunkt darstellt.
Im klassischen DDD sind Entitäten veränderlich (mutable), und viele Implementierungen verlassen sich aus Bequemlichkeit darauf. Ich ziehe es vor, meinen Code wann immer möglich unveränderlich (immutable) zu halten, weil es das Nachdenken über Zustand, Testen und Nebenläufigkeit viel sicherer macht, während das Kernprinzip von DDD, dass eine Entität durch ihre stabile Identität und nicht durch ihre Attribute definiert ist, dennoch respektiert wird.
Und nun zu unserem „Komponisten" – dem Aggregat.
Aggregat (Aggregate)#
In DDD ist ein Aggregat ein Cluster von Domänenobjekten – normalerweise Entitäten und Value Objects –, die als eine einzige Konsistenzgrenze behandelt werden. Das Aggregat stellt sicher, dass die Regeln und Invarianten der Domäne eingehalten werden, wann immer sich sein interner Zustand ändert.
Eine Invariante ist eine Geschäftsregel, die für eine Entität oder ein Aggregat immer wahr sein muss. Während Value Objects Regeln für ihre eigenen Daten durchsetzen können (zum Beispiel stellt eine E-Mail-Adresse sicher, dass sie ein gültiges Format hat), kann ein Aggregat Regeln auf höherer Ebene durchsetzen, die mehrere Entitäten oder Value Objects zusammen betreffen. Mit anderen Worten, die Daten könnten individuell gültig sein, aber im Kontext des Aggregats nicht konsistent.
class User private constructor(
val id: UserId,
val profile: UserProfile,
val isAdmin: Boolean,
) {
companion object {
// Invariante bei der Erstellung durchsetzen
fun create(
id: UserId,
profile: UserProfile,
isAdmin: Boolean
): UserCreationResult {
if (isAdmin && !profile.email.value.contains("@business_email.com"))
return UserCreationResult.InvalidAdminEmail
return UserCreationResult.Success(
User(id, profile, isAdmin)
)
}
}
// Befehl innerhalb des Aggregats
fun promoteToAdmin(newEmail: EmailAddress? = null): UserPromotionResult {
val email = newEmail ?: profile.email
val updatedProfile = profile.changeEmail(email)
if (!updatedProfile.email.value.contains("@business_email.com"))
return UserPromotionResult.InvalidAdminEmail
return UserPromotionResult.Success(
User(
id = id,
profile = updatedProfile,
isAdmin = true,
)
)
}
}
sealed interface UserCreationResult {
data class Success(val user: User) : UserCreationResult
object InvalidAdminEmail : UserCreationResult
}
sealed interface UserPromotionResult {
data class Success(val user: User) : UserPromotionResult
object InvalidAdminEmail : UserPromotionResult
}In diesem Beispiel gehen alle Erstellungen und Zustandsänderungen durch typsichere Fabriken und Befehle, um sicherzustellen, dass Invarianten niemals umgangen werden. Es ist sehr wichtig, dass unsere Domäne die Konsistenz wahrt und die Daten während ihres gesamten Lebenszyklus gültig bleiben.
Die versiegelten Ergebnistypen (sealed result types) machen explizit und selbstdokumentierend, welche Ergebnisse möglich sind, und ermöglichen es dem Compiler, die Behandlung sowohl von Erfolgs- als auch von Fehlerfällen zu erzwingen. Die direkte Instanziierung von User wird durch den private constructor verhindert, sodass jede Instanz die Validierungslogik in create oder promoteToAdmin durchlaufen muss.
Aggregate selbst haben auch Grenzen, die wir respektieren müssen. Sie können nicht einfach ein Aggregat in ein anderes einbetten, da jedes Aggregat für seine eigenen Invarianten und Konsistenzregeln verantwortlich ist. Ein Team-Aggregat kann beispielsweise User-Aggregate nicht direkt enthalten; es behält nur Referenzen auf deren IDs.
class Team private constructor(
id: TeamId,
name: TeamName,
memberIds: Set<UserId> // Referenzen auf User-Aggregate durch ID
) {
companion object {
fun create(
id: TeamId,
name: TeamName,
memberIds: Set<UserId>
): Team {
// kann robustere Validierung sein
require(memberIds.isNotEmpty()) { "Team must have at least one member" }
return Team(id, name, memberIds)
}
}
fun addMember(userId: UserId): Team =
Team(id, name, memberIds + userId)
fun removeMember(userId: UserId): Team =
Team(id, name, memberIds - userId)
}Dies hält die Regeln klar: Team setzt seine eigenen Invarianten durch, während User seine eigenen durchsetzt, und sie interagieren sicher über IDs, anstatt ihre internen Zustände zu vermischen. Es ist, als würde man jedem Aggregat seinen eigenen Arbeitsbereich geben – sie können zusammenarbeiten, aber niemals dem anderen auf die Füße treten.
Abgesehen von Aggregaten, Domänen-Entitäten und Value Objects sehen Sie möglicherweise manchmal die Service-Klassen der Domänenschicht. Sie werden für Logik verwendet, die normalerweise nicht in den Aggregaten untergebracht werden kann, aber dennoch eine Art Geschäftslogik ist. Zum Beispiel:
class ShippingService {
fun calculatePrice(
order: Order,
shippingAddress: ShippingAddress,
shippingOption: ShippingOption,
): Price {
return if (order.product.country == shippingAddress.country)
order.price
else order.price + someFee
}
}Wir werden an dieser Stelle nicht über die Nützlichkeit oder Effektivität von Services oder Aggregatoren auf Domänenebene diskutieren. Behalten Sie es einfach im Hinterkopf, bis wir an den Punkt kommen, an dem wir diese Ansätze zu einem Ganzen kombinieren.
Aber das ist so ziemlich alles – die Implementierung kann von Projekt zu Projekt variieren, und das Einzige, was ich als Regel für alles verwende, ist Unveränderlichkeit, wann immer möglich.
Probleme#
Blutleere Domänen-Entitäten (Anemic Domain Entities)#
Das Blutleere Domänenmodell (Anemic Domain Model) ist ein häufiges Anti-Pattern im Domain-Driven Design (DDD), bei dem die Domänenobjekte – Entitäten und Value Objects – auf passive Datencontainer reduziert werden, denen jegliches Verhalten fehlt und die nur Getter und Setter (falls zutreffend) für ihre Eigenschaften enthalten. Dieses Modell wird als „blutleer" bezeichnet, weil es darin versagt, die Geschäftslogik zu kapseln, die eigentlich innerhalb der Domäne selbst leben sollte. Stattdessen wird diese Logik oft in separate Service-Klassen ausgelagert, was zu mehreren Problemen im Gesamtdesign führt.
Um dieses Problem besser zu verstehen: Was genau ist schlecht an blutleeren Domänen-Entitäten? Lassen Sie uns das überprüfen:
- Mögliche Komplexität beim Verständnis dessen, wozu eine Domänen-Entität fähig ist: Wenn Logik über Controller oder UseCases verteilt ist, ist es schwieriger, die Verantwortlichkeiten der Entität nachzuvollziehen, was das Verständnis und das Debugging verlangsamt (bedenken Sie auch, dass es abgesehen von der IDE schwierig ist, die Geschäftslogik nachzuschlagen, die Sie in irgendwelche Controller oder UseCases gesteckt haben, was Code-Reviews viel schwieriger macht).
- Kapselung ist gebrochen: Entitäten halten nur Daten ohne Verhalten, was die Geschäftslogik in Services drängt und die Struktur schwerer wartbar macht. Das bedeutet, dass Sie die Logik über UseCases/Controller/usw. hinweg abgleichen und sicherstellen müssen, dass die Geschäftslogik tatsächlich korrekt geändert wird.
- Schwieriger zu testen: Wenn Verhalten verstreut ist, wird das Testen einzelner Features schwieriger, weil die Logik nicht innerhalb der Entität selbst gruppiert ist.
- Wiederholung von Logik: Geschäftsregeln werden oft über Services/UseCases hinweg wiederholt, was zu unnötiger Wiederholung und höheren Wartungskosten führt.
Ein Beispiel für eine schlechte Geschäfts-Entität:
sealed interface TimerState : State<TimerEvent> {
override val alive: Duration
override val publishTime: UnixTime
data class Paused(
override val publishTime: UnixTime,
override val alive: Duration = 15.minutes,
) : TimerState {
override val key: State.Key<*> get() = Key
companion object Key : State.Key<Paused>
}
data class ConfirmationWaiting(
override val publishTime: UnixTime,
override val alive: Duration,
) : TimerState {
override val key: State.Key<*> get() = Key
companion object Key : State.Key<ConfirmationWaiting>
}
data class Inactive(
override val publishTime: UnixTime,
) : TimerState {
override val alive: Duration = Duration.INFINITE
override val key: State.Key<*> get() = Key
companion object Key : State.Key<Inactive>
}
data class Running(
override val publishTime: UnixTime,
override val alive: Duration,
) : TimerState {
override val key: State.Key<*> get() = Key
companion object Key : State.Key<Running>
}
data class Rest(
override val publishTime: UnixTime,
override val alive: Duration,
) : TimerState {
override val key: State.Key<*> get() = Key
companion object Key : State.Key<Rest>
}
}Dies sind einfach Container mit Daten über Cadento-Zustände. Die Frage ist: Wie können wir diese blutleere Domänen-Entität in eine reichhaltige verwandeln?
In diesem Fall hatte ich für Zustände einen anderen Controller, der alle Übergänge und Ereignisse behandelte:
class TimersStateMachine(
timers: TimersRepository,
sessions: TimerSessionRepository,
storage: StateStorage<TimerId, TimerState, TimerEvent>,
timeProvider: TimeProvider,
coroutineScope: CoroutineScope,
) : StateMachine<TimerId, TimerEvent, TimerState> by stateMachineController({
initial { TimerState.Inactive(timeProvider.provide()) }
state(TimerState.Inactive, TimerState.Paused, TimerState.Rest) {
onEvent { timerId, state, event ->
// ...
}
onTimeout { timerId, state ->
// ...
}
// ...
})Abgesehen von seinem guten Aussehen verletzt es die DDD-Prinzipien – ein Domänenobjekt sollte nicht nur Daten, sondern auch Verhalten repräsentieren. Die Entität sollte wie folgt aussehen:
sealed interface TimerState : State<TimerEvent> {
override val alive: Duration
override val publishTime: UnixTime
// Jetzt kann die Geschäftsentität selbst auf Ereignisse reagieren;
// Diese Funktionen sind 'Aggregate' aus DDD;
onEvent(event: TimerEvent, settings: TimerSettings): TimerState
onTimeout(
settings: TimerSettings,
currentTime: UnixTime,
): TimerState
data class Paused(
override val publishTime: UnixTime,
override val alive: Duration = 15.minutes,
) : TimerState {
override val key: State.Key<*> get() = Key
companion object Key : State.Key<Paused>
override fun onEvent(
event: TimerEvent,
settings: TimerSettings,
): TimerState {
return when (event) {
TimerEvent.Start -> if (settings.isConfirmationRequired) {
TimerState.ConfirmationWaiting(publishTime, 30.seconds)
} else {
TimerState.Running(publishTime, settings.workTime)
}
else -> this
}
}
override fun onTimeout(
settings: TimerSettings,
currentTime: UnixTime,
): TimerState {
return Inactive(currentTime)
}
}
// ...
}Hinweis: Manchmal wird etwas Logik in UseCases gesteckt und es ist möglicherweise weniger offensichtlich als in diesem speziellen Fall.
Wenn man eine solche Entität betrachtet, versteht man schneller, was sie tut, wie sie auf Domänenereignisse reagiert und andere Dinge, die passieren können.
Aber was Geschäftsobjekte betrifft, haben Sie manchmal vielleicht das Gefühl, dass sie kein Verhalten haben, das Sie ihnen hinzufügen/verschieben können. Hier ist mein Beispiel für ein solches Objekt:
data class User(
val id: UserId,
val name: UserName,
val emailAddress: EmailAddress?,
val description: UserDescription?,
val avatar: Avatar?,
) {
data class Patch(
val name: UserName? = null,
val description: UserDescription? = null,
val avatar: Avatar?,
)
}Interessante Anmerkung: Es ist ein tatsächlicher Code aus meiner Benutzerdomäne mit einem solchen Problem.
Das potenzielle Problem ist, dass User und Patch Datencontainer ohne Geschäftslogik sind. Zunächst einmal verwende ich Patch nur in den UseCases, was bedeutet, dass es dort platziert werden sollte, wo es benötigt wird. Wenden Sie diese Regel für alles an – eine Deklaration ohne Verwendung auf der Ebene, die sie definiert, bedeutet, dass Sie etwas falsch machen.
Was User betrifft, gibt es keine Notwendigkeit, Aggregatfunktionen zu erstellen – Kotlins automatisch generierte copy-Methode ist mehr als genug, da Value Objects bereits validiert sind und es keine benutzerdefinierte Logik dafür für die gesamte Entität gibt.
Um mehr über dieses Problem zu erfahren, können Sie beispielsweise diesen Artikel lesen.
Ich würde hinzufügen, dass Sie versuchen sollten, blutleere Domänen-Entitäten zu vermeiden, sich aber gleichzeitig nicht dazu zwingen sollten – wenn es nichts zu aggregieren gibt, fügen Sie keine Aggregate hinzu. Erfinden Sie kein Verhalten, wenn nichts hinzuzufügen ist – KISS gilt immer noch.
Ignorieren der allgegenwärtigen Sprache (Ubiquitous Language)#
Ubiquitous Language, ein Schlüsselkonzept in DDD, wird oft ignoriert. Das Domänenmodell und der Code sollten dieselbe Sprache wie die Geschäftsinteressengruppen verwenden, um Missverständnisse zu reduzieren. Das Versäumnis, den Code an der Sprache der Domänenexperten auszurichten, führt zu einer Diskrepanz zwischen der Geschäftslogik und der tatsächlichen Implementierung.
Einfach ausgedrückt sollten Namen auch für Nicht-Programmierer leicht verständlich sein. Dies ist besonders hilfreich bei großen Projekten mit mehreren Teams mit unterschiedlichen Kenntnissen, Fähigkeiten und Verantwortlichkeiten.
Das ist eine Kleinigkeit, die man befolgen sollte, aber sehr wichtig. Ich würde hinzufügen, dass dieselben Konzepte nicht über verschiedene Domänen hinweg unterschiedliche Namen haben sollten – das ist selbst innerhalb eines Teams verwirrend.
Kommen wir nun zu einem anderen Ansatz, den ich in meinen Projekten verwende – Hexagonale Architektur:
Hexagonale Architektur#
Die Hexagonale Architektur, auch bekannt als Ports and Adapters, verfolgt einen anderen Ansatz bei der Strukturierung von Anwendungen im Vergleich zu herkömmlichen Ansätzen. Es geht darum, die Kern-Domänenlogik von externen Systemen zu isolieren – sodass die Kerngeschäftslogik nicht von Frameworks, Datenbanken oder anderen Infrastrukturbelangen abhängt. Dieser Ansatz fördert Testbarkeit und Wartbarkeit und passt gut zu DDD, da der Fokus auf der Geschäftslogik bleibt.
Es gibt zwei Arten von Ports – Inbound (eingehend) und Outbound (ausgehend).
- Inbound Ports definieren die Operationen, die die Außenwelt auf der Kerndomäne ausführen kann.
- Outbound Ports definieren die Dienste, die die Domäne von der Außenwelt benötigt.
Der Unterschied zwischen DDD und Hexagonaler Architektur in der Isolationsstrategie ist konzeptionell derselbe, aber letztere hebt ihn auf die nächste Ebene. Die Hexagonale Architektur definiert, wie Sie mit Ihrem Domänenmodell kommunizieren sollten.
Wenn Sie also beispielsweise auf einen externen Dienst oder eine Funktion zugreifen müssen, um etwas in Ihrer Domäne zu tun, gehen Sie wie folgt vor:
interface GetCurrentUserPort {
suspend fun execute(): Result<User>
}
class TransferMoneyUseCase(
private val balanceRepository: BalanceRepository,
private val getCurrentUser: GetCurrentUserPort
) {
suspend fun execute(): ... {
val currentUser = getCurrentUser.execute()
val availableAmount = balanceRepository.getCurrentBalance(user.id)
// ... Überweisungslogik
}
// ...
}UseCases werden typischerweise als Inbound Ports betrachtet, da sie Operationen oder Interaktionen darstellen, die von der Außenwelt initiiert werden. Die Benennung und Implementierung kann jedoch variieren.
In meinen Projekten bevorzuge ich es, keine weitere Terminologie einzuführen, und erstelle normalerweise einfach ein Interface eines Repositorys, das ich von außen benötige:
interface UserRepository {
suspend fun getCurrentUser(): Result<User>
// ... andere Methoden
}Ich konsolidiere alles in einem einzigen Repository, um unnötige Klassenerstellung zu vermeiden und eine klarere Abstraktion für die meisten Leute zu bieten, die mit dem Konzept eines Repositorys vertraut sind.
Es ist vielleicht nicht immer der Fall, dass Sie ein Repository von einem anderen Feature oder System aufrufen müssen. Manchmal möchten Sie vielleicht eine andere Geschäftslogik aufrufen, die das erledigt, was Sie benötigen (was viel besser sein kann), bekannt als UseCases. In diesem Szenario ist es üblich, ein anderes Interface als im ersten Beispiel zu haben.
Hier ist die Visualisierung:
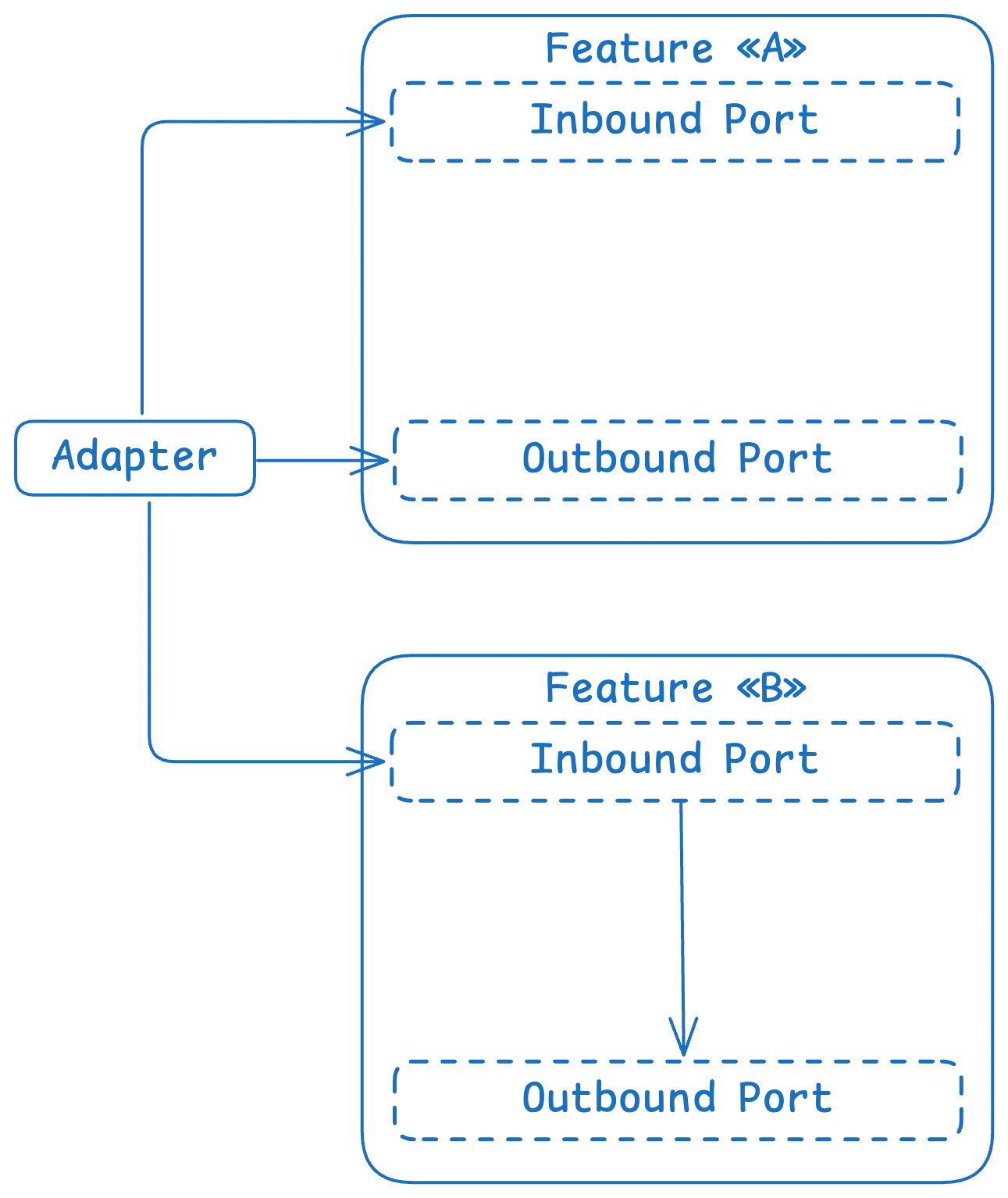
Hinweis: Übrigens ist die andere Terminologie für 'Feature' der 'Bounded Context' aus dem DDD. Sie bedeuten im Grunde dasselbe.
Das Beispiel für die Definition und Verwendung von Ports, das dem obigen Schema folgt:
// FEATURE «A»
// Outbound Port, um den Benutzer von einem anderen Feature (Bounded Context) zu erhalten
interface GetUserPort {
fun getUserById(userId: UserId): User
}
class TransferMoneyUseCase(private val getUserPort: GetUserPort) : TransferService {
override suspend fun transfer(
val userId: UserId, val amount: USDAmount
): Boolean {
val user = getUserPort.getUserById(request.userId)
if (user.balance >= request.amount) {
println("Transferring ${request.amount} to ${user.name}")
return true
}
println("Insufficient balance for ${user.name}")
return false
}
}Die Implementierung von Ports erfolgt durch Adapter – sie sind im Grunde nur Bindeglieder, die Ihr Interface implementieren, um mit einem externen System zu arbeiten. Die Benennung einer solchen Schicht kann variieren – von einfachem Data oder Integration bis hin zu direktem Adapters. Sie sind ziemlich austauschbar und hängen von den spezifischen Namenskonventionen des Projekts ab. Diese Schicht implementiert normalerweise andere Domänen und verwendet andere Ports, um das zu erreichen, was sie benötigt.
Hier ist ein Beispiel für die Implementierung von GetUserPort:
// UserService ist der Service von einem anderen Feature (B)
// Adapter befinden sich normalerweise in einem separaten Modul, da sie abhängig sind von
// einer anderen Domäne, um eine direkte Kopplung zu vermeiden.
class GetUserAdapter(private val getUserUseCase: GetUserUseCase) : GetUserPort {
override fun getUserById(userId: String): User? {
return userService.findUserById(userId)
}
}Features sind also nur auf der Daten-/Adapter-Ebene gekoppelt. Der Vorteil dabei ist, dass Ihre Domänenlogik unverändert bleibt, egal was mit dem externen System passiert. Das ist ein weiterer Grund, warum die Ports der Domäne eigentlich nicht allem entsprechen sollten, was das externe System will – es liegt in der Verantwortung des Adapters, damit umzugehen. Damit meine ich, dass zum Beispiel die Funktionssignatur anders sein kann als die, die im externen System verwendet wird, solange es natürlich möglich ist, damit zu arbeiten.
Eine weitere Sache ist, dass es wichtig ist zu überlegen, wie man mit Domänentypen umgeht. Features sind selten vollständig von anderen Arten von Features isoliert. Wenn wir zum Beispiel ein Geschäftsobjekt namens User und ein Value Object UserId haben, müssen wir oft die ID des Benutzers wiederverwenden, um Informationen in Bezug auf den Benutzer zu speichern. Dies schafft die Notwendigkeit, einen Weg zu finden, diesen Typ in verschiedenen Teilen des Systems wiederzuverwenden.
In einer idealen Hexagonalen Architektur sollten verschiedene Domänen unabhängig voneinander existieren. Das bedeutet, dass jede Domäne ihre spezifischen Definitionen der von ihr verwendeten Typen haben sollte. Einfacher ausgedrückt: Es erfordert, dass Sie diese Typen jedes Mal neu deklarieren, wenn Sie sie benötigen.
Das erzeugt eine Menge Duplizierung, Boilerplate beim Konvertieren jedes Typs zwischen separaten Domänen, Probleme bei der Validierung (insbesondere wenn sich Anforderungen im Laufe der Zeit ändern, könnte man etwas übersehen) und ist einfach ein großer Schmerz im Leben eines jeden Entwicklers.
Der Rat ist, dass Sie nicht all diesen Regeln folgen sollten, solange Sie keinen Nutzen darin sehen. Suchen Sie nach einem glücklichen Mittelweg im Umgang damit; wie ich damit umgegangen bin, werden wir im folgenden Teil besprechen.
Probleme#
Falsches mentales Modell#
Was die Fehler betrifft, die ich am häufigsten sehe – Entwickler verstehen nicht, dass es bei den Domänen-/Anwendungsschichten nicht nur um eine physische Aufteilung geht, sondern um das richtige mentale Modell. Lassen Sie es mich erklären:
Mentales Modell ist eine konzeptionelle Darstellung der Funktionsweise oder Struktur verschiedener Teile des Systems, die miteinander interagieren (einfach gesagt, wie der Code von denen wahrgenommen wird, die ihn verwenden). Es unterscheidet sich von einem physischen Modell darin, dass ein physisches Modell physische Interaktion beinhaltet – zum Beispiel das Aufrufen einer bestimmten Funktion oder das Implementieren eines Moduls, d.h. alles, was von Hand gemacht wird.
Ein häufiges Problem im Softwaredesign ist es, der Domänen-/Anwendungsschicht zu erlauben, Kenntnis von der Datenspeicherung oder -beschaffung zu haben, was das Prinzip der Trennung der Belange verletzt. Der Fokus der Domäne sollte auf der Geschäftslogik liegen, unabhängig von Datenquellen. Sie könnten jedoch Beispielen wie LocalUsersRepository oder RemoteUsersRepository begegnen, sowie entsprechenden UseCases wie GetCachedUserUseCase oder GetRemoteUserUseCase in der Anwendungsschicht (falls Repositories in der Domäne liegen, platziere ich sie normalerweise dort, wo ich sie verwende – in der Anwendungsschicht, aber das Problem bleibt). Obwohl dies ein spezifisches Problem lösen mag, verletzt es das mentale Modell der Domäne, das unabhängig von der Datenquelle bleiben sollte.
Dasselbe gilt für DAOs im Kontext von Frameworks wie androidx.room. Sie verletzen nicht nur die Regel, keine Aussage über die Datenquelle zu machen, sondern verletzen zusätzlich die Regel der Unabhängigkeit von Frameworks.
Ihre Repositories/UseCases sollten sich von der Datenquelle fernhalten, auch wenn es in Situationen, in denen die Implementierung nicht direkt in der Domänen-/Anwendungsschicht liegt, in Ordnung zu sein scheint.
Meine Implementierung#
Nachdem ich die Erklärung der Ansätze, die ich verwende, abgeschlossen habe, möchte ich zu meiner tatsächlichen Implementierung übergehen und wie ich mit der Reduzierung unnötigen Boilerplates und Abstraktionen umgegangen bin.
Beginnen wir damit, die Schlüsselideen jedes diskutierten Ansatzes zu definieren:
- Clean Architecture: Teilen Sie Ihren Code nach ihrer Verantwortlichkeit in verschiedene Schichten auf (Domain, Data, Presentation)
- Domain-driven Design: Die Domäne sollte nur Geschäftslogik enthalten, alle Typen sollten über ihren gesamten Lebenszyklus hinweg konsistent und valide sein.
- Hexagonale Architektur: Strenge Regeln für den Zugriff auf innere und äußere Welten.
Sie passen größtenteils perfekt zusammen, was ein Schlüssel zum Schreiben von gutem Code ist.
Die Struktur der Cadento-Features (verschiedene Domänen) ist wie folgt:
- domain (Domäne)
- data (Implementiert alles, was mit Speicher- oder Netzwerkverwaltung zu tun hat, einschließlich Submodulen mit DataSources)
- database (Integration mit SQLDelight, automatisch generierte DataSources)
- network (eigentlich habe ich das in Cadento nicht, weil es durch das Cadento SDK ersetzt wird, aber wenn nicht, würde ich es hinzufügen)
- dependencies (Integrationsschicht mit Koin)
- presentation (UI mit Compose und MVI)
Ich mag diese Struktur bisher, aber vielleicht möchten Sie die UI von ViewModels unterscheiden, um verschiedene UI-Frameworks pro Plattform verwenden zu können; ich plane das nicht, also lasse ich es so, wie es ist. Aber falls ich in Zukunft vor einer solchen Herausforderung stehe, ist es für mich nicht schwer, da ich in den ViewModels nicht von Compose abhängig bin.
Das Hauptproblem, das ich erlebt habe, war der Boilerplate, den ich bei der Implementierung der Hexagonalen Architektur hatte – ich habe Typen kopiert und eingefügt, was mich fragen ließ: 'Brauche ich das wirklich?'. Also habe ich mir folgende Regeln ausgedacht:
- Ich habe gemeinsame Kerntypen, die zwischen verschiedenen Systemen wiederverwendet werden; es ist eine Art kombinierte Domäne der am meisten benötigten Typen.
- Der Typ kann nur dann gemeinsam sein, wenn er in den meisten Domänen verwendet wird, ein Problem mit der Duplizierung der Validierung hat und überhaupt keine komplexe Struktur aufweist (manchmal gibt es Ausnahmen, aber normalerweise nicht viele).
Was meine ich mit 'komplexer Struktur'? Normalerweise benötigt Ihre Domäne, die den Typ einer anderen Domäne anfordert, nicht alles, was in dem gegebenen Typ beschrieben ist. Zum Beispiel möchten Sie vielleicht den Typ 'User' teilen, samt seinen Value Objects, aber größtenteils benötigen andere Domänen nicht alles vom Typ User und wollen vielleicht zum Beispiel nur den Namen und die ID. Ich versuche solche Situationen zu vermeiden, und selbst wenn etwas bereits in den Kerndomänentypen vorhanden ist, würde ich lieber einen eigenen Typ mit Informationen erstellen, die meine bestimmte Domäne benötigt. Aber was die Validierung angeht, teile ich fast alle semantischen Value Objects.
Sie können diese Idee für größere Projekte erweitern, indem Sie nicht nur gemeinsame Kerntypen erstellen, sondern Typen für spezifische Bereiche, in denen eine Gruppe Ihrer Subdomänen (Bounded Contexts) arbeitet.
Zusammenfassend lässt sich sagen, dass ich Value Objects, die dieselben Validierungsregeln haben, in einem gemeinsamen Modul wiederverwende; ich versuche, mein Modul für gemeinsame Kerntypen nicht mit allem zu überladen. Es sollte immer einen glücklichen Mittelweg geben.
Außerdem habe ich in meinen Projekten den Begriff 'Inbound Ports' nicht. Ich ersetze sie vollständig durch UseCases:
class GetTimersUseCase(
private val timers: TimersRepository,
private val fsm: TimersStateMachine,
) {
suspend fun execute(
auth: Authorized<TimersScope.Read>,
pageToken: PageToken?,
pageSize: PageSize,
): Result {
val infos = timers.getTimersInformation(
auth.userId, pageToken, pageSize,
)
val ids = infos.map(TimersRepository.TimerInformation::id)
val states = ids.map { id -> fsm.getCurrentState(id) }
return Result.Success(
infos.mapIndexed { index, information ->
information.toTimer(
states.value[index]
)
},
)
}
sealed interface Result {
data class Success(
val page: Page<Timer>,
) : Result
}
}Hinweis: Dies ist ein Beispiel aus dem Cadento Backend
Es verletzt weder die Hexagonale Architektur noch DDD, was es zu einem guten Weg macht, zu definieren, wie die Außenwelt auf Ihre Domäne zugreift. Es hat die gleiche Bedeutung und das gleiche Verhalten wie ein Inbound Port.
Was die Outbound Ports betrifft, habe ich es genauso gemacht, wie ich es zuvor in den Beispielen gezeigt habe.
Fazit#
In meinen Projekten bevorzuge ich es, die Dinge praktisch zu halten. Während Theorie und Abstraktion nützlich sind, können sie einfache Dinge verkomplizieren. Deshalb kombiniere ich die Stärken von Clean Architecture, DDD und Hexagonaler Architektur, ohne mich allzu streng an die Buchstaben zu halten. Nutzen Sie kritisches Denken, um festzustellen, was Sie tatsächlich benötigen und warum es Ihrem Projekt nützt, anstatt blind Empfehlungen zu folgen.
Verlinkte Erwähnungen1
Unverlinkte Erwähnungen0
Keine unverlinkten Erwähnungen.

